- POST
分散ストレージのためのインライン重複排除

SDSにおけるSSDの使いどころ – Part 3で少し触れたことがありますが、IzumoFSはインライン重複排除機能を備えています。これまでは一部の高価なバックアップアプライアンスやオールフラッシュストレージくらいにしか実装されていなかった高度な機能であり、SDSでこれを実現している製品は現在のところ非常に限られています。
多くの方にとって分散ストレージとインライン重複排除というのは見慣れない組み合わせかと思いますが、実はこの2つは相性がよく、単純なストレージ容量削減に留まらないメリットがあります。今回の記事では、IzumoFSにおけるインライン重複排除の位置づけについて解説したいと思います。
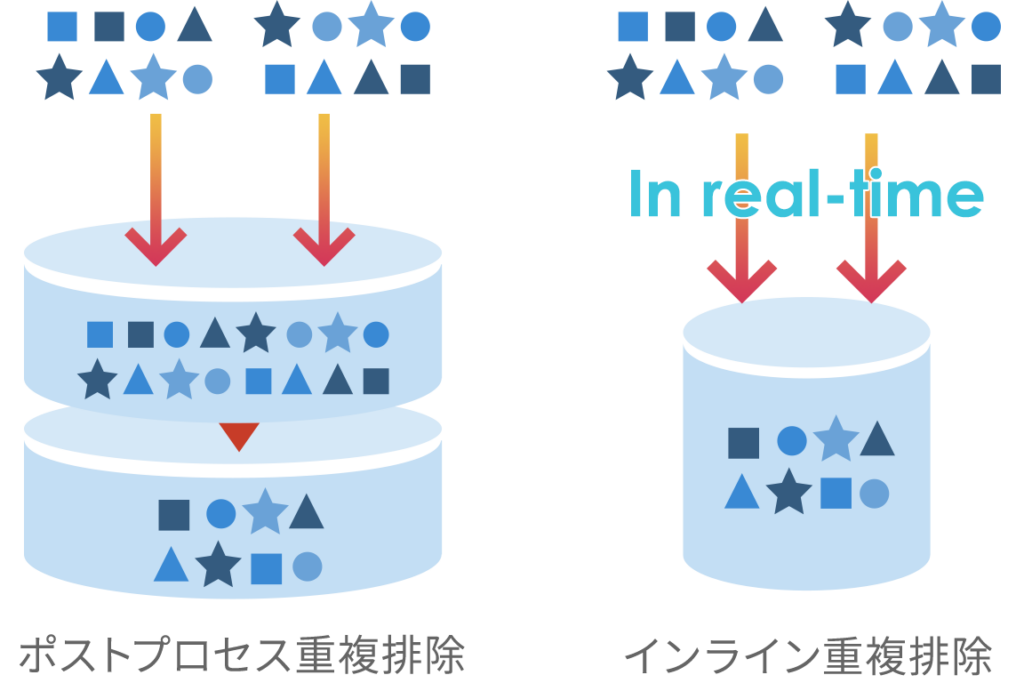
ポストプロセス重複排除とインライン重複排除
今となってはポピュラーになったインライン重複排除ですが、あらためて一般的なポストプロセス重複排除とその特徴を比較してみます。
ポストプロセス重複排除
一旦データをストレージに書き込み、その後にバッチ処理で重複排除処理を行います。一時的には重複データ分の容量が必要となるため、常に余裕を持った容量設計が必要となります。インライン重複排除に比較するとコントローラへの負荷が低く、重複排除率も高いことがメリットです。
インライン重複排除
データをディスクやSSDに書き込む前に重複排除処理を行います。ポストプロセス重複排除に比べるとコントローラへの負荷はかかりますが、一時的にも重複データの書き込みは発生しないため、容量効率の向上や書き込み回数低減によるSSDの長寿命化に寄与します。その他にも重複したデータが共通のキャッシュに乗るため、キャッシュヒット率が向上し、結果的に読みこみ性能の向上にもつながります。
分散ストレージとネットワーク負荷
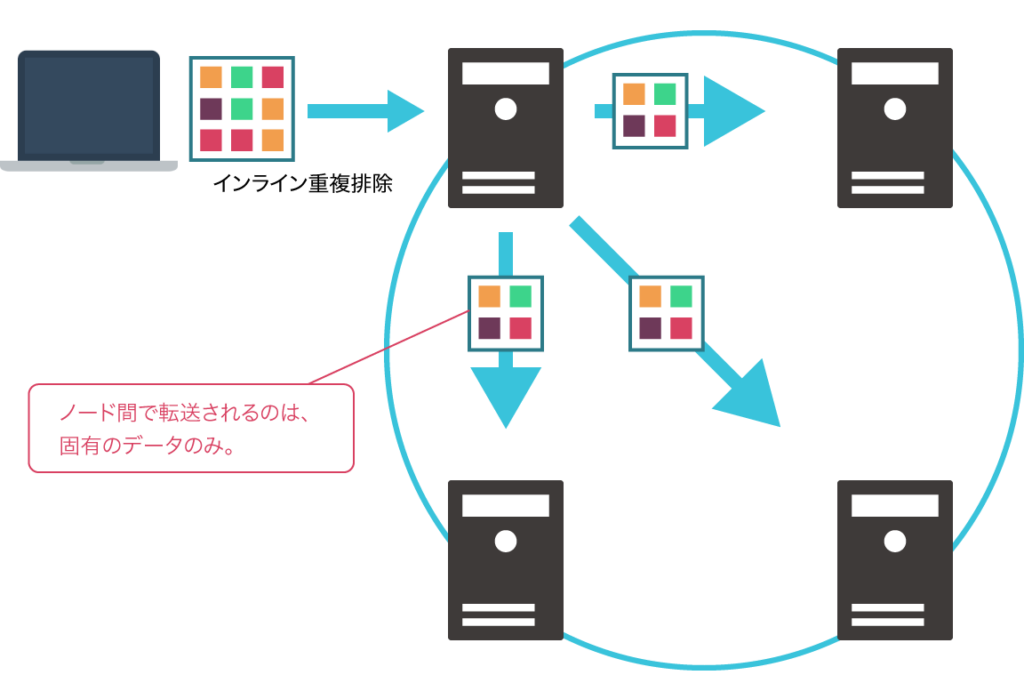
分散ストレージの課題の一つとして、ノード間の通信が挙げられます。複数のノードを束ねて一つのストレージをつくる都合上、ノード間は頻繁に通信を行っており、冗長化方式などにもよりますがRead/Writeのタイミングでデータの転送が行われます。さらにノードの増減があるときにはデータリバランス処理が実行されますし、製品によってはこれらの処理を広域で行うこともあります。つまり分散ストレージはその性質上、ネットワークがパフォーマンスのボトルネックになりやすいといえます。この問題を避けるための対策として、製品によってはノード間通信の帯域の最低要件を1Gbps以上としたり、infiniBandで繋いだり、ノード間通信とクライアント通信のネットワークを分けたりと、場合によってはかなりリッチな環境が要求されます。
IzumoFSのインライン重複排除は、このような問題を軽減することを目的のひとつとして実装されています。インライン重複排除は一般的には容量削減やSSDの有効活用のために使われる技術ですが、IzumoFSのような分散ストレージにおいては、これらに加えてネットワーク負荷の低減という大きなメリットが存在します 1。
IzumoFSのインライン重複排除
書き込みデータの重複排除と分散処理のタイミングは書き込みポリシーによって選択されます。書き込み保証ポリシーはIzumoFSの内部的な設定値であり、本記事での詳細な解説は省きますが、大まかには(1)パフォーマンス重視、(2)一貫性重視の設定があります。本来的には結果整合性を許容するかどうかを決めるためのオプションですが、上述の通り、これらは重複排除と分散処理とも結びついており、(1)は重複排除後にデータを分散し、(2)はデータ分散後に重複排除を行います。書き込みデータはローカルメモリ上でハッシュ値計算され、クラスタ全体の既存データブロックのハッシュ値と同一であれば書き込みが省略されます。これらの処理はプロトコルや冗長化方式に依存せず実施されます。(2)のケースであれば初回の書き込み以降、(1)のケースなら常にノード間ネットワークにはクラスタ固有のデータのみを送信するため、ネットワーク帯域の使用を低く抑えることが可能です。
また、副次的な効果として、ランダムライトはメモリ上で処理され、その後シーケンシャルライトとしてHDDへ書き出されます。※3そのため、HDDの性能を引き出すことも可能となります。
インライン重複排除につきまとう懸念点として真っ先に挙げられるのが、CPU負荷ではないでしょうか。インライン重複排除機能を備えるストレージの多くは数kb~数十kb単位の重複排除処理を行うため、一般的にはそれなりのCPU負荷がかかるとされています。一方で、IzumoFSは意図的に重複排除の単位を1MBという比較的大きな値に設定しています。これはXeon E3シリーズ、メモリ16GB程度といった、SDSとしては比較的低いスペックでも常に数%のCPU負荷で重複排除が行えるように設計しているためです。
原則として重複排除の比較単位と重複排除率はトレードオフの関係にあります。数kb~数十kb単位で処理を行うストレージよりはIzumoFSの方が重複排除率は低いことが予測されます。IzumoFSのインライン重複排除のコンセプトとしては、容量を削減するというよりも、むしろ無駄なデータをネットワークに流さないことや、キャッシュヒット率の向上、IOのシーケンシャル化といった効果を期待しています。弊社としては、1MB単位での重複排除処理による限定的なCPU負荷をカバーして余りある性能面でのメリットがあると考えています。
重複排除の単位を大きくすることに依る重複排除率の低下についても、環境に依存するため一概にはいえませんが、弊社環境においてVMイメージで測定したケースでは70%程度の重複排除率がありました。1MBという重複排除単位においても、VDIのような環境では高い排除率を期待できます。ファイルサーバ用途でも、たとえばよくあるケースとして、ファイルを別ディレクトリにコピーした場合などにはメタデータ部分以外は重複データとなるので重複排除率は極めて高くなります。
インライン重複排除の効果が薄いケース
ここまでインライン重複排除のメリットを並べてきましたが、当然ながらこれだけで分散ストレージのネットワーク負荷に関するすべての懸念が解消されるわけではありません。たとえばリバランスなどにはIzumoFSでいえばノードリプレイス機能のような別のアプローチが必要となりますし、そもそも別のアプリケーションとネットワークを共用するのであれば、帯域使用率に制限をかけた方が簡単かもしれません。また、一般的に画像系データなどは重複排除が効きづらいと言われているので、前述のメリットを大きくは期待できません。個別の環境に対する構成については、お気軽にIzumoBASEまでお問合せ下さい。
さいごに
インライン重複排除の技術を理解することで、その効果をより大きく引き出すことが可能です。重複データをすべてノード間ネットワークに流してしまう従来型のSDSでは、どうしてもネットワークがパフォーマンスのボトルネックになりがちでした。インライン重複排除は一般的には容量削減やSSDの有効活用のために使われる技術ですが、分散ストレージにおいてはこれらに加えてネットワーク負荷の低減をはじめとした多くのメリットを享受できます。インライン重複排除を前提とした高価なバックアップアプライアンスやオールフラッシュストレージのような構成を汎用サーバで実現できるようになりますので、単なる容量削減機能ではなく、分散ストレージの適用用途を広げるための鍵となる機能といえるのではないでしょうか。
- IzumoFSはネットワークボトルネックを生む要素に対して、次の対策を施しています。インライン重複排除、分散キャッシュ、ノードリプレイス機能、書き込みポリシー設定。
- (2)の書き込み保証ポリシーは、主にVDIやデータベースといったアプリケーションからの要請がある場合に使用されます。
- メタデータはユニークな情報であるため、重複排除処理は行われません。ワークロードが異なるため、重複排除されるブロックデータとはRAIDグループをわけることを推奨しています。