- POST
無駄の無いBCP/DRとは?

かねてよりBCPの重要性が注目されています。技術的には円熟期に入りつつあり、クラウドの台頭という背景も影響して価格面でも以前より検討しやすくなっています。このような状況にある従来型BCPソリューションですが、メインストレージとは別にDRサイトへデータを移動するという構造上の制約により、運用負荷の増大は避けられません。今回の記事では、IzumoFSで実現する、従来の制約に縛られない新時代のBCPを紹介します。
これまでのBCP
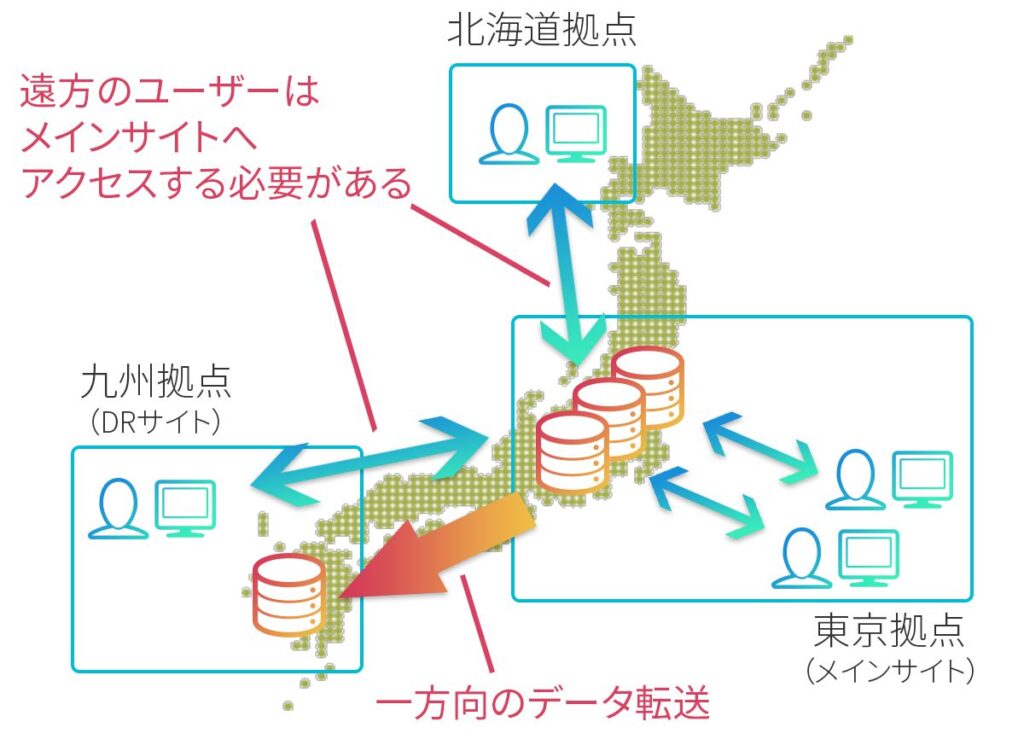
一般的にBCPを実現する方法として、テープバックアップ、クラウドバックアップ、バックアップ用ストレージ、ストレージ機能としてのレプリケーションなどの選択肢が考えられます。どの方式を選択するかはコスト、RPO(目標復旧時点)、RTO(目標復旧時間)、セキュリティポリシーなどの兼ね合いになりますが、多くの方は上記のように、DRサイトにバックアップ/レプリケーションする構成を思い浮かべるのではないでしょうか。
DRサイトのストレージは基本的に災害時以外にはデータを保存するだけの目的で使用されます。バックアップの効率化のために、メイン-DRサイトの多対一のバックアップやインライン重複排除によるデータ容量とネットワーク負荷の低減など、製品ごとに様々な工夫が施されています。
これらは実績のある安定したソリューションではありますが、構成上、下記のような制約があります。
- すべてのユーザがメインサイトへアクセスする必要がある
- DRサイトは災害時以外に活用不可(もしくは用途が限定的)なのでコストがかかる
- 非同期レプリケーション/バックアップ方式の場合、(2)に加えてRPO(目標復旧時点)とRTO(目標復旧時間)が増大する
- リストア手順やバックアップデータの管理が煩雑
IzumoFSのBCP
分散ストレージソフトウェアの中でも拠点間にノードを配置できるIzumoFSでは、上述の従来型方式とはBCPに対する考え方が異なります。下記がIzumoFSを用いた典型的な広域クラスタリングの構成です。
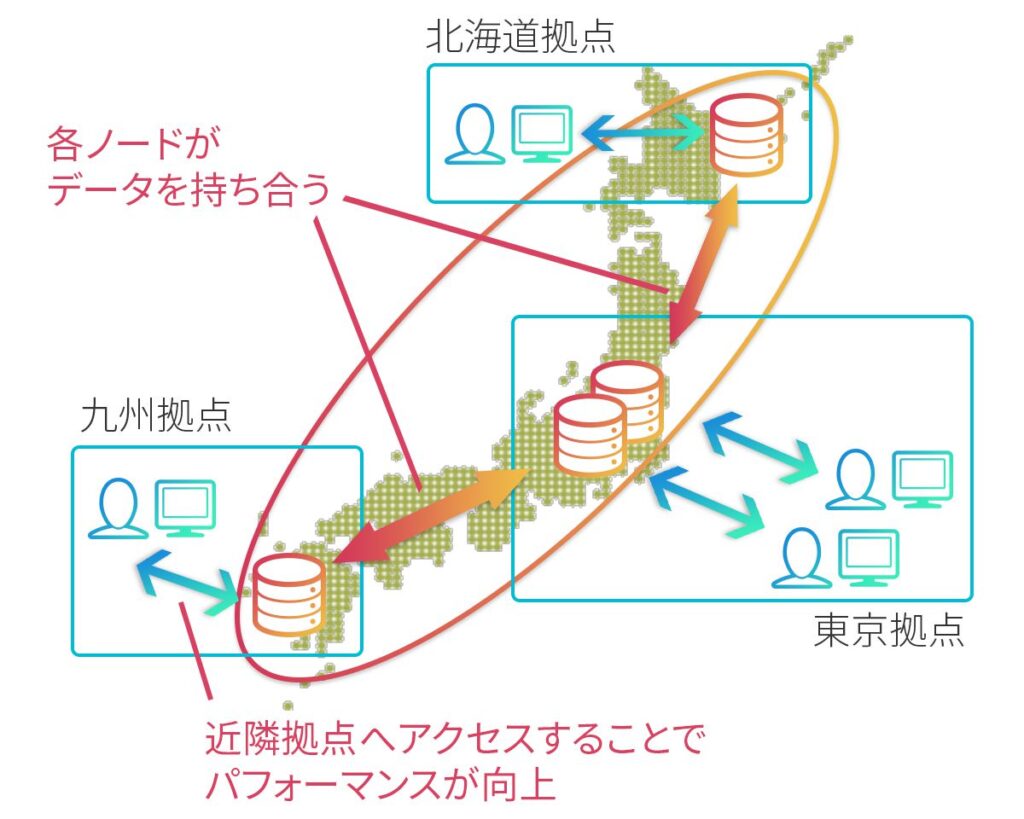
この構成により、ユーザは(1)から(4)までの従来型BCPの制約から解放されます。
1. 各ユーザは近隣拠点にアクセス可能
ユーザの分布に合わせたノード配置にすることで、ユーザ-ストレージ間のアクセス遅延を最小化します。従来のメインサイトにアクセスを集中させる方式では常にデータの「重力」の影響を受けてしまうので、離れた拠点のユーザほど性能が劣化します。
ただし、IzumoFSの方式でもノード数と冗長化の設定次第では、アクセスしたノードに目当てのデータが存在しないことが起こりえます。その場合にはノード間のネットワークを介してデータを持ってくる必要が生じます。とはいえデータの使用頻度が高ければ、結局は近隣ノードのキャッシュに乗ることになるので、IzumoFSを利用し続けることでクラスタ内のデータ配置が最適化されていきます。
2. DRサイトのノードはIzumoFSクラスタの容量、性能向上に寄与
遠隔拠点のノードはそのままメインストレージの一部として活用できるので、専用のバックアップストレージは不要です。BCPのための遠隔拠点配置がそのままメインストレージの容量と性能の向上に直結します。
3. 災害時にも被災拠点以外にアクセス可能なので、RPO(目標復旧時点)とRTO(目標復旧時間)がゼロとなる
IzumoFSは純粋なP2P構成を持っています。設置場所とは無関係にすべてのノードを平等に扱うため、特定拠点が利用不可となった場合でもユーザは意識することなくデータにアクセス可能です。
4. データリストア不要。バックアップはスナップショットで一元管理
万全のBCP対策を持つ企業でも、災害時にしか行わないデータリストアの手順を詳細に把握しているIT担当者は何名いるでしょうか。専用のバックアップストレージを導入している場合には、メインサイトのストレージとは異なるインターフェースにも精通しておく必要があります。
一方で、IzumoFSに特別なリストア手順は必要ありません。災害により特定拠点のノードがすべて失われたとしても、対応方法は日常的なノード交換作業と一切変わりません。
また、元データが失われると復元不可能となってしまうコピーオンライト方式のスナップショットは、図1の構成では拠点災害対策に使用できるものではありませんでした。しかし、IzumoFSの構成であれば拠点災害時にもデータロストには至りません。このような構成であれば、スナップショットの管理がすなわちバックアップデータの管理となります。
IzumoFSはスナップショットのバージョン管理(ブランチング)に対応しており、直感的に復元ポイントを管理することができます。
まとめ
これまではメインストレージのNext stepという位置づけだったBCPを、IzumoFSでは最小構成で即実現できるようになっています。さらに、万全のデータ保護を求めるお客様向けにはデータの暗号化を施したクラウドバックアップ機能を提供しています。
今回の記事が、これからのBCPあり方について考えるきっかけとなれば幸いです。
最後に、IzumoFSでの構成を見て、データ書き込み時の性能や一貫性保護について気になった方もいらっしゃるかもしれません。IzumoFSは書き込みポリシーの調整によってこれらに対応しているのですが、詳細については今後の更新で紹介していきたいと考えています。